Overview
My CV is generated by code, meaning everything is in plaintext and easily manageable by version control.
The final output I am looking for is a single document consisting of two pages. The first document is a single page text consisting of a brief introduction, commercial experience, other relevant experience and education; followed by second document, a skill tree.
| Document 1 | Document 2 |
|---|---|
 |
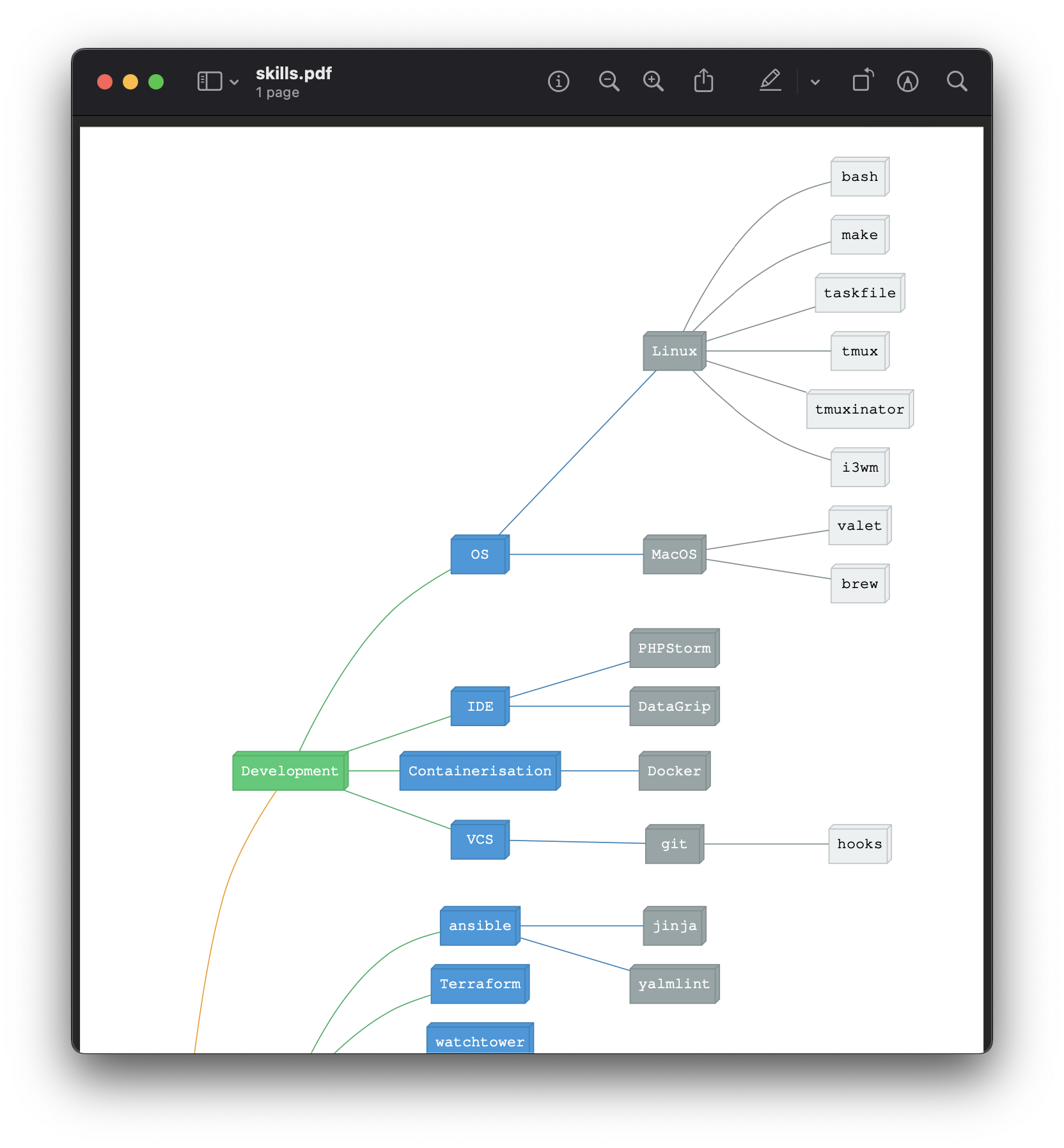 |
Skills
I have created a roadmap.sh inspired skill tree/graph, it can be seen on my homepage.
This is generated using graphviz with my tree/graph markup as a dot file.
My build process uses taskfile and it will generate various assets from dot files as a pdf, svg, and png.
Unfortunately dot doesn’t have variables, so I use an intermediate dot as source file, and run envsubst to build a true dot file.
skills.sh:
#!/usr/bin/env bash
export SKILLS_FONT_NAME="Cousine"
# etc.
envsubst < src/skills.dot > dot/skills.dot
Unfortunately I have decided to use a non-standard font here too… Obviously this is to be containerised… So I will need to install a font in a container for graphviz to be able to work with.
I have used a multi-stage build to accomplish this.
FROM bitnami/git:latest as font
RUN git -C /tmp clone https://github.com/googlefonts/cousine.git font
FROM nshine/dot:latest
# path inside repo with trailing slash
ARG font_path=fonts/ttf/unhinted/variable_ttf/
USER 0
RUN mkdir /usr/share/fonts/newfont
COPY --from=font /tmp/font /tmp/font
RUN find /tmp/font/$font_path -name '*.ttf' \
-exec install -v -m644 {} /usr/share/fonts/newfont \;
USER 1000
RUN fc-cache -v -f
CMD ["sh"]
- First container is just a lightweight container to
git clonea font from Google fonts Github repository. - Then I will copy the
gitrepo from the first stage into the basedotimage used to build the assets and install the font and update font cache.
Then the image, and skills tree assets are built like using a file like this using task:
---
version: 3
output: group
vars:
WEB_COLOR: '#41403e'
DOCKER_IMAGE_SKILLS: alistaircol/skills
DOCKER_IMAGE_GRAPHVIZ: dot
DOCKER_RUN: |
docker run \
--rm \
--tty \
--volume="$(pwd):/app" \
--workdir="/app" \
--user=$(id -u):$(id -g)
DOCKER_RUN_SKILLS: "{{.DOCKER_RUN}} {{.DOCKER_IMAGE_SKILLS}}"
tasks:
lint:
cmds:
- "{{.DOCKER_RUN}} {{.DOCKER_IMAGE_YAMLLINT}} ."
interactive: true
default:
cmds:
- task: docker_pull
- task: build_dot_image
- task: clean
- task: build_dot
- task: build_png
- task: build_svg
- task: build_pdf
# the rest is omitted
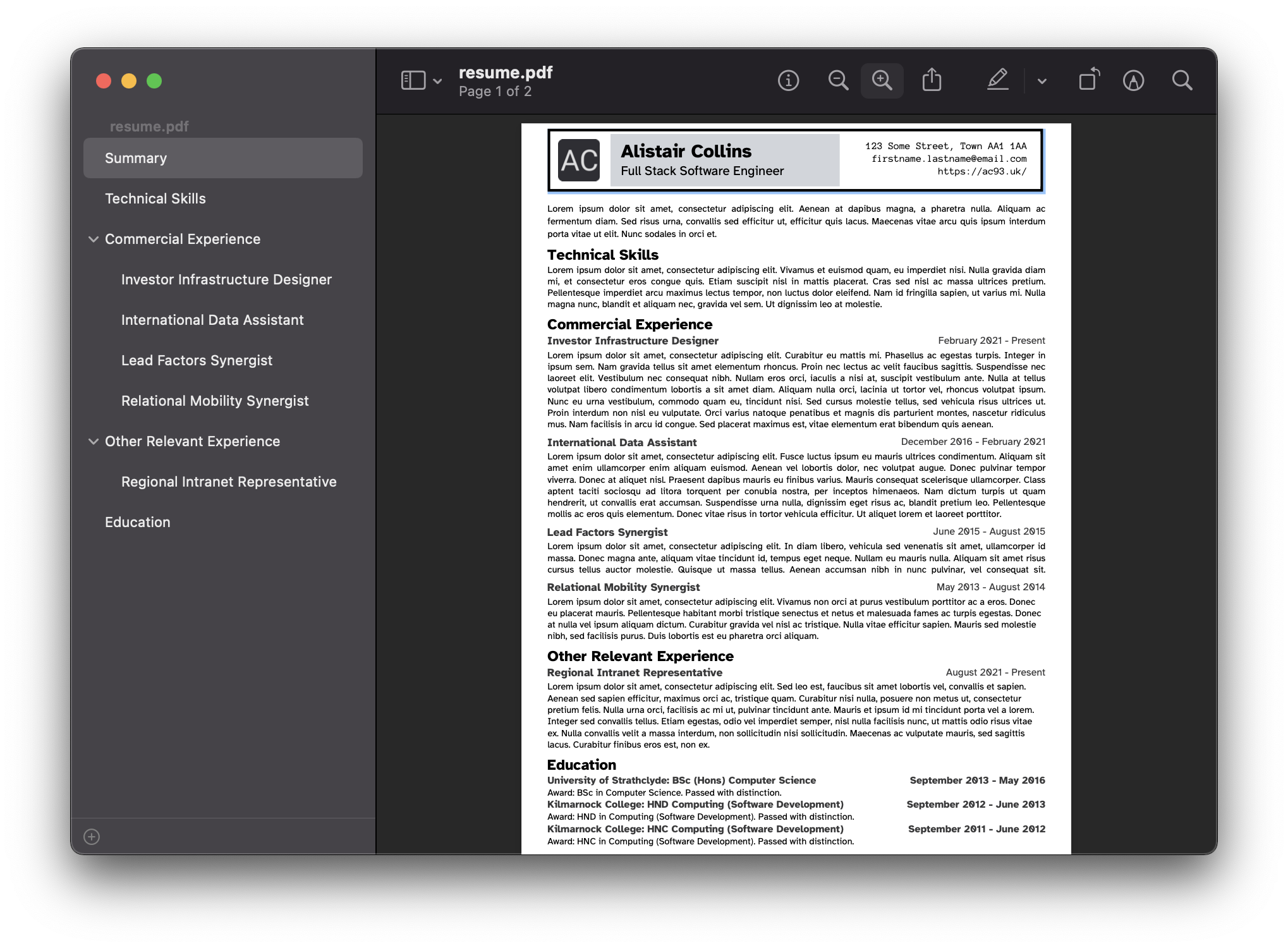
The PDF output looks like this:
I use pdftk to modify the PDF metadata too:

This is a stand-alone repository here and it has CI/CD.
Experience
This is a single page (with some great difficulty squeezing everything in) that is built in PHP by using TCPDF.
Using TCPDF is relatively well documented (though not the easiest to use with the enormous amount of arguments in most method calls) so I won’t explain in great detail.
This is a relatively straightforward process, although I use a non-standard font, so this involves converting a ttf using tools/tcpdf_addfont.php.
The main entry looks like this:
public function build()
{
$this->addHeaderDecoration();
$this->addHeaderContent();
$this->addSummary();
$this->addTechnicalSkills();
$this->addCommercialExperience();
$this->addOtherRelevantExperience();
$this->addEducation();
$this->pdf->setPDFVersion('1.4');
}
- The
addHeaderContentincludes some personal information, so this is read fromenv. - I explicitly use
setPDFVersion, so I can manipulate the document later on, the default is1.7.
This is one of the more laborious ways to generate such a document, but the main benefits of generating this way over, say, an HTML/CSS page that is converted to a PDF using a headless browser such as by puppeteer:
- File size is usually much smaller.
- Much greater control of layout.
- Adding bookmarks.
- Customising certain meta attributes.
- Some security features and other things I haven’t investigated.
Modifying the metadata with pdftk again:

Concatenation
This is a relatively simple process. I use mnuessler/pdftk to combine the separate documents into a single document.
| Document 1 | Document 2 |
|---|---|
|
|
Metadata
Likely no one will care, but I use mnuessler/pdftk to get and update the metadata of the documents with dump_data_utf8 and update_info_utf8 respectively.
Get Metadata
Basically I dump the metadata of the document and delete all lines starting with Info and merge them with a file of the metadata Info attributes I want to change.
This file will be used in the next step to update a document’s metadata.
# Reusable docker run command
docker_run = docker run --rm \
$(shell tty -s && echo "-i" || echo) \
-v "$(shell pwd):/app" \
-w "/app"
get_meta_skills_pdf:
${docker_run} -t mnuessler/pdftk build/skills.pdf dump_data_utf8 \
| sed '/^Info/d' \
| cat .pdf/skills.txt - > build/skills.meta
.pdf.skills.txt:
InfoBegin
InfoKey: Creator
InfoValue: https://ac93.dev
InfoBegin
InfoKey: Producer
InfoValue: Alistair Collins - with Graphviz
InfoBegin
InfoKey: Title
InfoValue: Alistair Collins - Skills
InfoBegin
InfoKey: Subject
InfoValue: Skills
InfoBegin
InfoKey: Author
InfoValue: Alistair Collins
Update Metadata
Just update the document’s metadata to be that which we dumped previously in to the build/skills.meta file.
You may need to move/copy the file since this update cannot be done ‘in-place’ (I append the .tmp suffix to the file after dumping the metadata).
# Reusable docker run command
docker_run = docker run --rm \
$(shell tty -s && echo "-i" || echo) \
-v "$(shell pwd):/app" \
-w "/app"
set_meta_skills_pdf:
${docker_run} mnuessler/pdftk build/skills.pdf.tmp \
update_info_utf8 build/skills.meta \
output build/skills.pdf
| Before | After |
|---|---|
 |
|
How it could look after updating the metadata after concatenating the documents:

Local Development
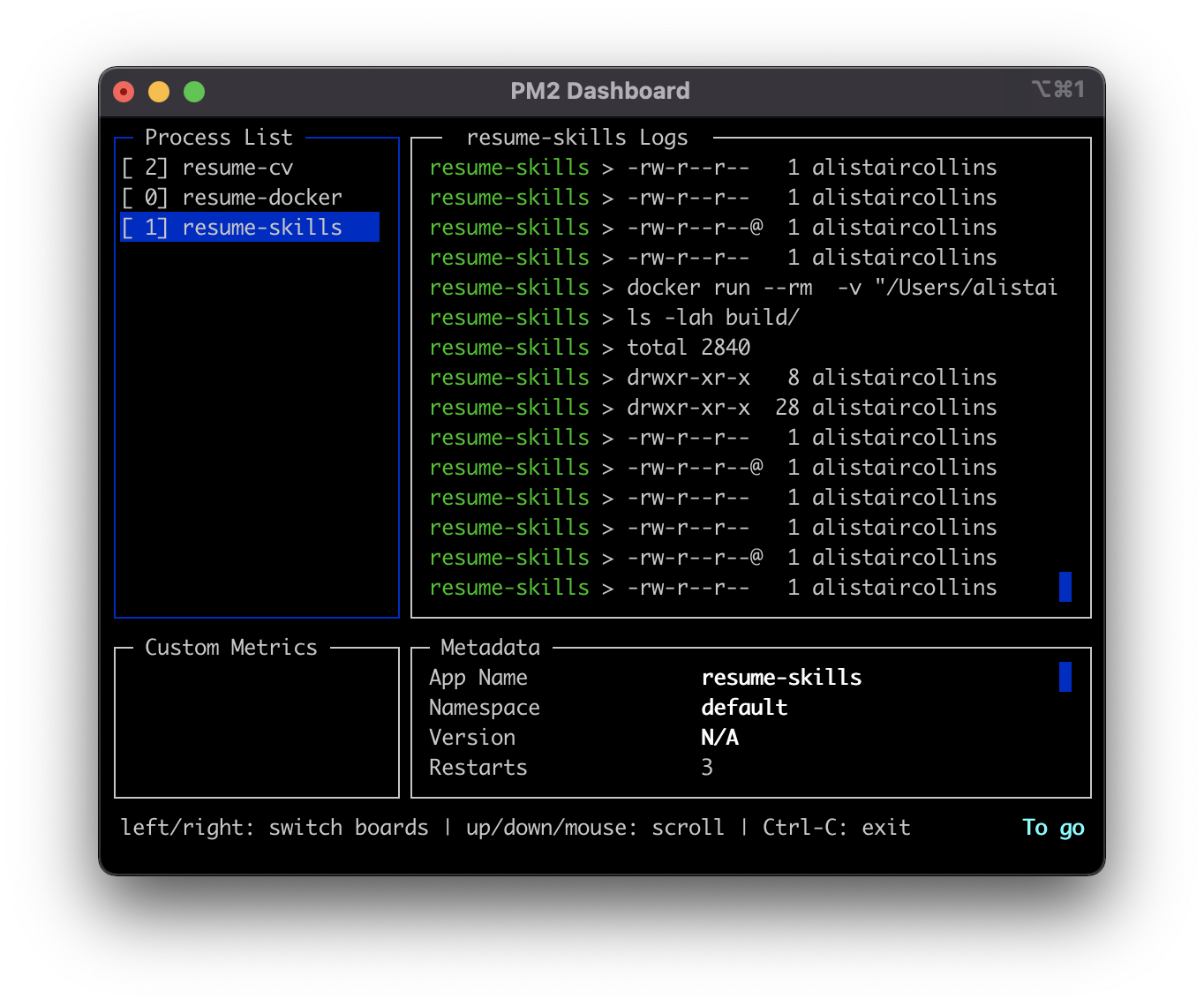
If this isn’t overkill enough then strap in. I primarily develop on Mac, so I use pm2 and fswatch to rebuild pre-requisites when things are changed.
brew install fswatch
npm i -g pm2
The ecosystem.config.js will watch:
Dockerfiletomake skills_docker- i.e. rebuild docker container that is used to build skills tree
skills.tmpl,skills.shtomake skills_dot skills_png skills_svg skills_pdf- i.e. the
dotfile used to build the skills tree
- i.e. the
.env,src/tomake build- i.e. to make the CV and combines CV and skill into a single document
// pm2 start ecosystem.config.js
// pm2 stop ecosystem.config.js
// pm2 status all
module.exports = {
apps: [
{
name: "resume-docker",
script: "fswatch --one-event --event=Updated Dockerfile && make skills_docker",
},
{
name: "resume-skills",
script: "fswatch --one-event --event=Updated skills.sh skills.tmpl && make skills_dot skills_png skills_svg skills_pdf",
},
{
name: "resume-cv",
script: "fswatch --one-event --event=Updated .env src/ && make build",
}
]
};
CI/CD
A workflow is configured to run when a tag is pushed.
I use this command below to see the most recent tags, and to see which will be the next logical release.
git --no-pager tag | grep -v "^v" | sort -V
Once I’m happy with the local build, I will tag and push:
git tag 1.2.0 -m 'good enough'
git push origin 1.2.0
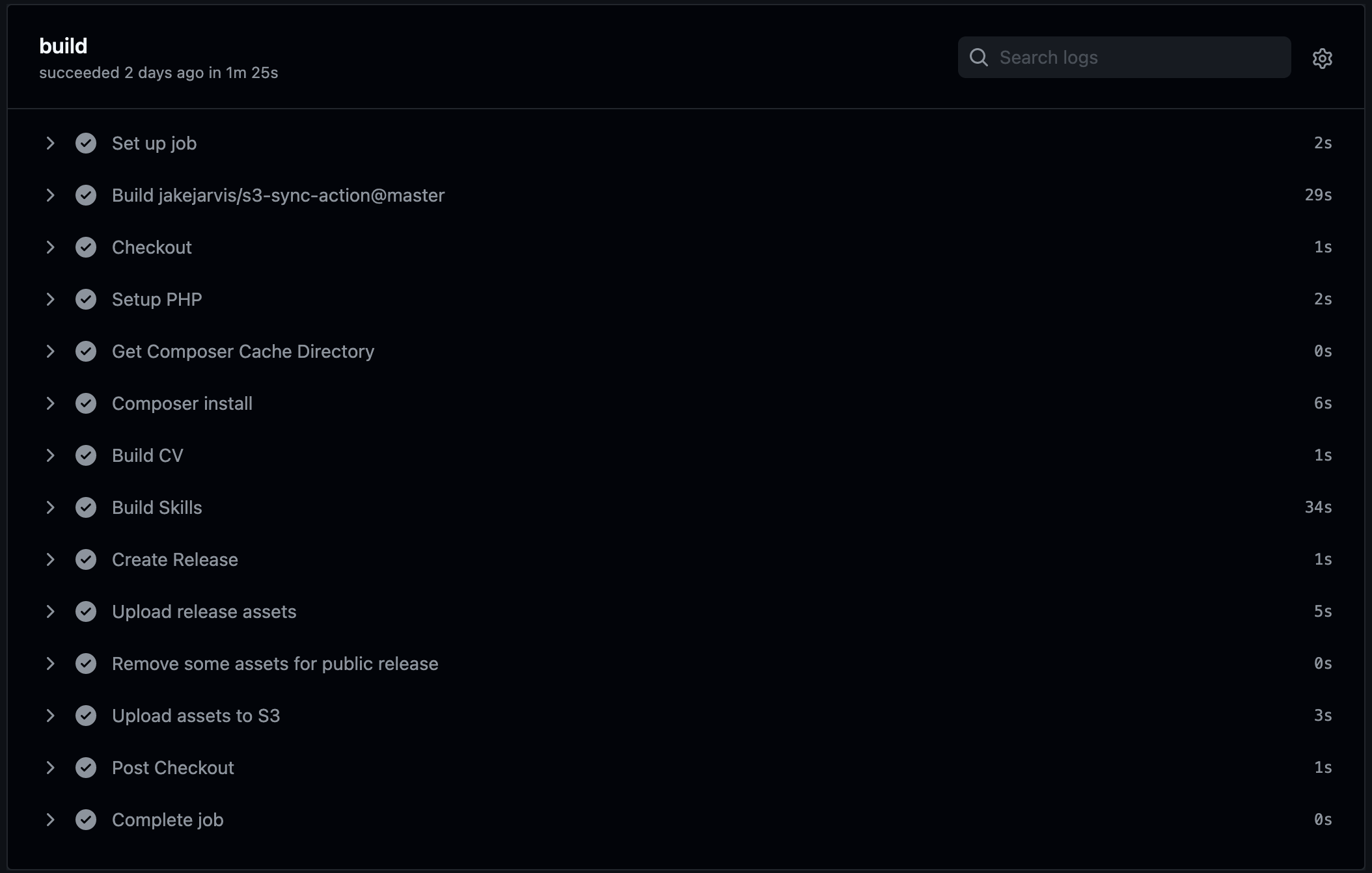
The workflow will build all these assets, and included they are then included in a new release. Then a certain subset of these assets are uploaded to an s3 bucket for use on my website and github profile.
Pretty cool (I think) 😎.
Next step… dark mode CV…
Samples
- one page: Skills
- one page: CV
- two pages: CV & Skills